process 마다 page table이 존재 하는데 이는 Main memory에 저장되어 있다.(table의 크기가 커서)
모든 data/instruction의 access는 두번의 memory access 가 필요 한데
하나는 page table 접근, 다른 하나는 Data/instruction 접근이다.
이렇게 매번 두번씩 메모리 접근이 수행되면 Overhead가 매우 커진다는 문제가 있다.
그럼 이를 해결할 수 있는 방법이 뭐가 있을까?
HW의 도움을 받을 수 있는 방법이 있다. MMU안에 special fast-lookup hardware cache를 이용하는 것이다.
이를 associative memory 또는 Translation look-aside buffers(TLBs)라고 한다.
즉 아이디어는 page table를 caching 하자는 것이다.(MMU안에서)
일반적으로 TLB는 32, 64, 128개의 entry를 가지며 실제 table 보다 크기가 작다. 따라서 replacement policy가 필요하다.
TLB는 page table의 요소가 TLB의 어떤 위치에든 갈 수 있게 해주는 full associative method에 의해 관리되며 다음과 같이 구성된다.

이때 Other bit으로는 Valid bits, protection bits, address-space identifier(ASID), dirty bit을 의미한다.
VPN : virtual page number
PFN : page frame number를 의미한다.
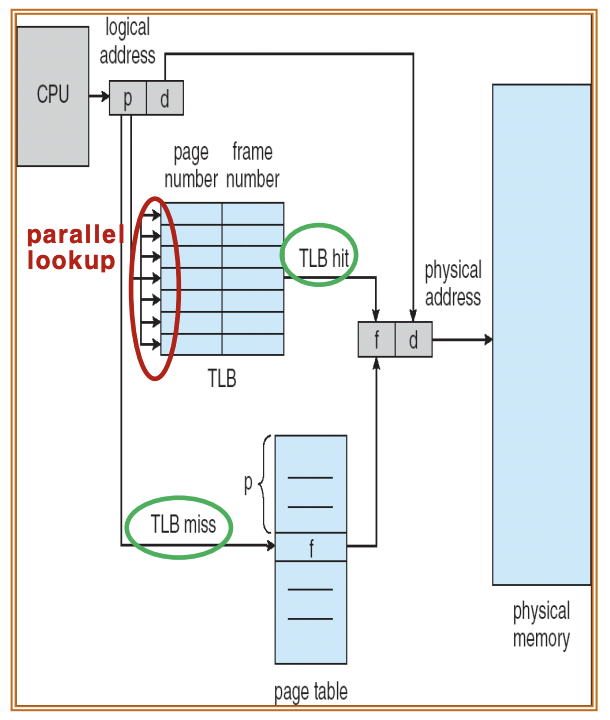
TLB를 이용한 Paging은 왼쪽과 같다.
1. cpu에서 instruction을 읽어 온다.
2. VPN(virtual page number)를 이용해 TLB에서 찾는다.
3. 만약 TLB에 존재하는 VPN이면 PFN(page frame number)를 얻어와서 translation 해준다. (TLB hits)
3(2). 만약 존재하지 않는 VPN이면 page table에 직접 Access를 해서 PFN을 얻어와 translation 해준다.(TLB miss)
-> memory 두번 access이므로 extra over head!
** TLB의 몇개의 ENTRY는 kernel code의 permanent fast acess를 위해 미리 예약 되어 있다.
TLB를 이용한 메모리 접근 코드는 다음과 같다.

코드를 하나하나 살펴보자.
1. virtual address에서 vpn mask와 shift를 이용해 VPN 파트를 분리한다,
2. TLB에서 VPN의 여부 확인 한다.
3-8:TLB HIT에 해당하는 코드 이다.
TlbEntery에 접근 가능하다면 Virtual address에서 Offset mask 를 이용해 OFFSET을 분리하고
Tlbentry의 PFN(page frame number)를 가져와 OFFSet 과 결합하여 Physical address를 만들어 낸다.
그리고 해당 주소로 memory access를 진행한다.
9-17 : TLB MISS에 해당하는 코드이다.
PTBR 이란 값은 Page table의 위치를 알고 있는 변수이므로 해당 위치에서 (VPN * sizeof(PTE))값을 더해 Page table entry 주소(PTEaddr)를 구한다.
그리고 해당 주소에 접근해서 Page table entry의 내용을 PTE 변수에 가져온다.
PTE.Valid 값이 참이면 VPN/PFN/ProtectBits으로 구성하여 TLB에 삽입한다.
그리고 instruction을 다시 실행하여 TLB hit이 되게 함으로서 translation을 진행한다.
TLB를 활용한 예시를 한번 살펴보자.
array에 access 하는 경우이다.

virtual memory에 배열이 왼쪽과 같이 저장이 되어 있고 offset이 16bytes임으로 보아 page 크기가 16bytes 이고
virtual address는 VPN/OFFSET으로 구성되는데 VPN에 해당하는 bit은 page가 16개 이므로 4개의 bit으로 표현하고
OFFSET에 해당하는 bit은 한 page가 16바이트 이므로 4bit으로 표현한다.
즉 virtual address는 총 8bit으로 구성되었다.
a[0]에 접근할 때는 TLB miss 가 날 것이고 page table에 접근 해서 PFN을 얻어 VPN/PFN/other bit을 만들어 TLB에 넣을 것이다.
이후 a[0]을 다시 접근해서 코드를 진행하고
a[1] a[2]까지는 TLB에 존재하는 VPN이므로 TLB hit이 일어날 것이다.
a[3]에서 다시 Miss가 날 것이고 a[4] a[5] a[6] 은 TLB hit이 일어날 것이다.
a[7]에서 다시 Miss가 날 것이고 a[8] a[9]는 TLB hit이 일어날 것이다.
즉, 오른쪽 코드를 전체 진행했을 경우 3 misses 7 hit이고 TLB hit rate 는 70%임을 확인할 수 있고,
memory에 spatial locality에 의해 TLB의 performance가 향상했음을 알 수 있다.
위에서 보았듯이 CACHE design 할 때 locality를 생각할 수 밖에 없다.
locality는 다음과 같다.

'CS > [OS]Operating System(OS 운영체제)' 카테고리의 다른 글
| [OS] multi-level page tables (2) (0) | 2022.12.04 |
|---|---|
| [OS]Multi-level Page Tables (1) (0) | 2022.12.04 |
| [OS] Paging : Smaller Tables (0) | 2022.12.04 |
| [OS] TLBs : Faster Translations-Issues (0) | 2022.11.29 |
| [OS] TLBs : Faster Translations - HW-managed/SW-managed (0) | 2022.11.29 |



